Either Unreal Engine 5 AI has become more intuitive or I am spending right time with the AI. Recently I made a zombie game first person shooter prototype with UE 5.4.4. The natively playable prototype binaries can be found at this GitHub page (available for Linux, Mac, and Windows). But, as with several different software, the versioning usually, in some sense, can make it non-intuitive.
Disclaimer: This is not to imply that what follows, the concept of Observer Aborts, is an example of different implementation with different versions of UE. From forums it seems like, but I am not sure.
The story starts with the following image

If you are new to Unreal’s behavior trees, might I refer to here, here, and here. We are interested in the BT_ZombieBehavior window containing the behavior tree for zombie AI. Clearly, as per the decorator in Sequence node (third level from ROOT), the Move To task shouldn’t be executed if Target Enemy (query key) is not set, meaning set to NULL.
This wasn’t happening practically in the game. The zombies were still moving towards the player (chase mode) when Target Enemy was not set. Native logging verified that this is case. Now, following my friend’s noble advice, on doing some forum reading, I stumbled upon https://forums.unrealengine.com/t/ai-blackboard-based-condition-does-not-abort/511343.
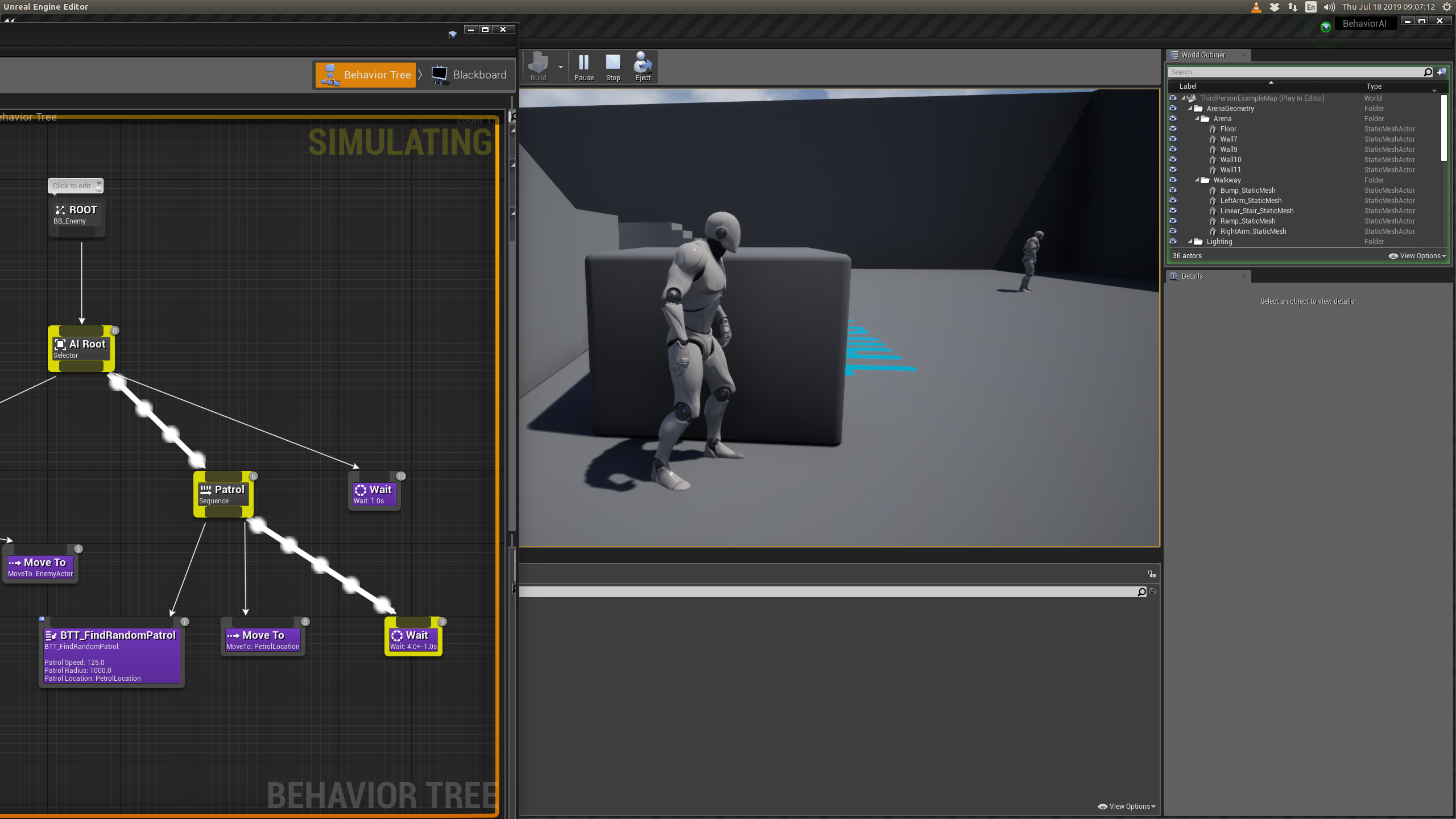
Based upon the observation in the forum thread, consider the following image

All we have now is to understand the purpose of setting the field Observer Aborts to self in UE 5.4.4. For that we refer to official UE documentation page. The page mentions that setting the field to Self, aborts self (node) and any subtrees, which is Move To task in this context, running under the node. This means that even if Target Enemy is NULL, Move To task is being executed with whatever Target Enemy was set earlier and, if the task is not completed, AI won’t halt the zombie, leading to an infinite pursuit, even when the pawn vehicle is out of sight.
Upon further forums’ reading, for instance this, seems like an optimization (caching?) for changing decorator conditions, which probably is our case, for re-evaluation of “if Target Enemy is set”, which updates appropriately if Observer Aborts is set to self.
Extra Credit
If you have been observing pedantically enough, in the second level from ROOT, Selector node has been replaced by Sequence which, in practical sense, is a mental exercise only. In this context, there is no practical difference between them. Because, when using Selector (at second level), until the Move To task is completed, the behaviour tree control won’t go to the Sequence with BTTask_Halt child, unless the Target Enemy is set to NULL, in which case, Move To task will be aborted, moving the control to the parent of halt task.
Even simpler version of behaviour tree, in this context, which gives the same result is like so

Since self abort stops the execution of Move To task, BTTask_Halt, which essentially sets the MoveTo actor to NULL, has no need. Probably self abort does that already.



 to
to  :
:

 with probability
with probability  or a random action with probability
or a random action with probability 


![Q(A)\leftarrow Q(A) + \frac{1}{N(A)}\left[R - Q(A)\right]](https://s0.wp.com/latex.php?latex=Q%28A%29%5Cleftarrow+Q%28A%29+%2B+%5Cfrac%7B1%7D%7BN%28A%29%7D%5Cleft%5BR+-+Q%28A%29%5Cright%5D&bg=eeeeee&fg=666666&s=0&c=20201002)