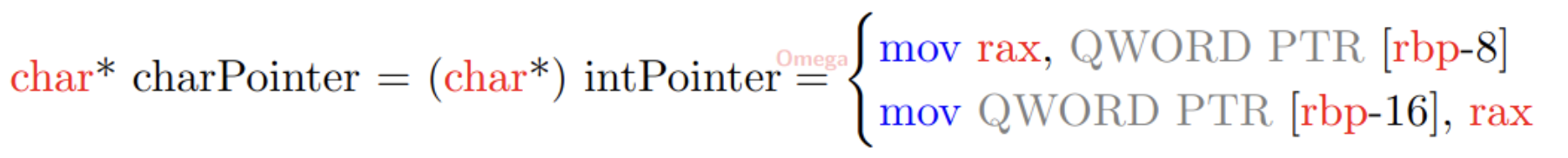C++ programming language, just like a regular English language, has concept of “genericity”. For instance, the word “bank“, in English, is generic in the sense that the word can mean an institution (noun) or an activity (verb). The meaning is inferred from the context of the word usage.
Genericity introduces certain degree of flexibility in the language. The flexibility covers etymologically related or even, in some cases, unrelated meanings (or links?). For instance, “bank” may refer to financial institution as a noun or, related activity as a verb, or edge of a river as an unrelated (to the institution) noun. Basically, genericity can be viewed as minimizing the vocabulary and maximizing the utility or means to control the complexity of a language.
Similarly, in C++ language, there is a notion of generic programming which is implemented by using templates. Consider the following C++ code
template<typename T>void Exchange(T& a, T& b){ T temp = a; a = b; b = temp;}
This function, Exchange, can be used for floats or ints alike to exchange the value like so
int a = 10;int b = 20;float c = 100;float d = 200;Exchange(a, b); // a becomes 20 and b becomes 10Exchange(c, d); // c becomes 200 and d becomes 100
Note how the function Exchange is used for both ints and floats type. Based on the context, int and float calls, compiler generates two copies of Exchange function, one each for int and float type respectively, using which the values of variables are exchanged.