This post is continuation of this blog-post. Here we will understand the algorithm behind the emergent behavior, called Reinforcement Learning (RL). The situation of shooting colored boxes is equivalent to k-armed bandit problem which can be stated as
You are faced repeatedly with a choice among k different options, or actions. After each choice you receive a numerical reward chosen from a stationary probability distribution that depends on the action you selected. Your objective is to maximize the expected total reward over some time period, for example, over 1000 action selections, or time steps.
The reward for this game is: 100 for shooting red box and -10 for shooting blue box. The AI agent can access the scoreboard and take the actions accordingly. Based on the rewards, the agent generates the expected value associated to an action. This value is, in a way, the memory of all the rewards obtained when that particular action was performed. In more complicated systems, the rewards my be even probability based.
For RL, it is not only important to take those actions which have high expected value associated with them (exploiting the knowledge-base), but, once in a while, it is necessary to pick a random action irrespective of the associated expected value (exploration). This makes sure that the system doesn’t get stuck in the local optimum. For instance in case of correlated rewards, some actions when performed in certain sequence might yield better rewards. Later in this post it is shown why exploring leads to global optimum configuration knowledge!
For the problem at hand, the rewards are deterministic and static. So the RL algorithm is as follows (this algorithm can be found in Sutton’s book, section 2.4 (working link July 23, 2019))
Initialize, for
to
:
Repeat forever:
with probability
or a random action with probability





![Q(A)\leftarrow Q(A) + \frac{1}{N(A)}\left[R - Q(A)\right]](https://s0.wp.com/latex.php?latex=Q%28A%29%5Cleftarrow+Q%28A%29+%2B+%5Cfrac%7B1%7D%7BN%28A%29%7D%5Cleft%5BR+-+Q%28A%29%5Cright%5D&bg=eeeeee&fg=666666&s=0&c=20201002)
In Unreal Engine, the above algorithm can be easily implemented and is posted here (specifically look the member function UMAIBrainComponent::TickComponent). The game is played in the Unreal Editor where the rendered arena image is
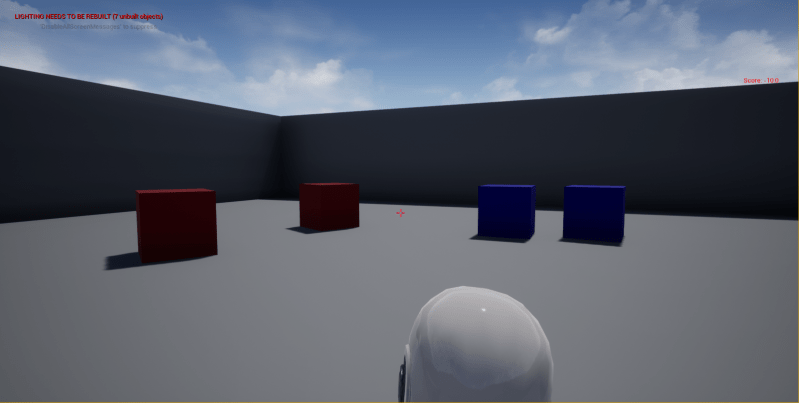
The first two red boxes on left are levers 0 and 1 and last two boxes on right are 3 and 2 levers.
When the game begins, the control is passed over to AI agent who, as per the logic flowing through Tick function, starts shooting the boxes implementing RL technique. The log of first 22 iterations of the shootouts performed on July 23, 2019 can be found here.
Log Analysis:
We start with 0th iteration. An action (lever) is chosen at random because all the estimates are set to 0. The reward obtained is 100 and the estimate of action 0 is updated. For the next 3 iterations, the action with the highest expected value is chosen by the agent which results in pawn firing at first red box. But during 5th (marked with iteration number 4) iteration, the agent explores and randomly* chooses action 2 (last blue box) in spite of its expected value as 0. As result reward is -10. But then again it starts exploiting the knowledge-base and obtains higher rewards. Then again during iteration number 11 it chooses action 3 (second last blue box) and gets negative reward. Again, it continues with highest reward action selection (based on knowledge-base).
Finally during iteration number 19, it chooses action 1 (second red box) and gets reward 100. The estimates are updated (as can be see from next iteration’s maximum estimates ) and now, agent has global high estimates in the knowledge-base which couldn’t have been registered if agent weren’t exploring.
In the next blog-post of this series, we will see the visual implementation of this logic (natural to UE codebase).
* Ignore the 1 – epsilon text typo in the log text.